https://www.youtube.com/watch?v=nBor4jfWetQ&list=PLoROMvodv4rOaMFbaqxPDoLWjDaRAdP9D&index=2
위 영상을 보며 정리한 내용입니다.
GloVe: Global Vectors for Word Representation
Motivation
- Word2Vec 등의 기존 모델들은 지역적 문맥(window-based context)에 집중
- corpus 전체의 전역 통계(global co-occurance statistics)를 활용하면 더 안정적이고 의미적으로 잘 정렬된 벡터 생성 가능
- 단어들의 동시 등장 확률(co-occurance probability)를 활용해 벡터를 학습시킴
Key idea
- 단어의 의미는 그 단어가 어떤 단어들과 자주 같이 등장하는지에 의해 드러남
- 단순히 두 단어의 동시 등장 횟수만 보는 것이 아니라, 두 단어가 제3의 단어와 얼마나 더 자주/덜 자주 같이 등장하는지를 나타내는 비율이 의미를 잘 표현해줌
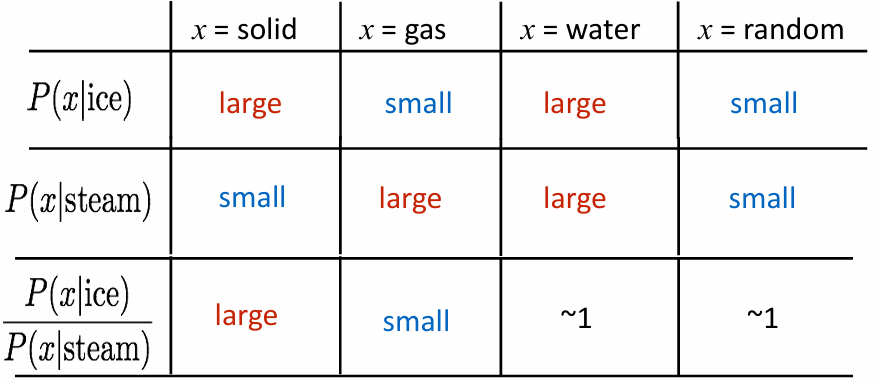
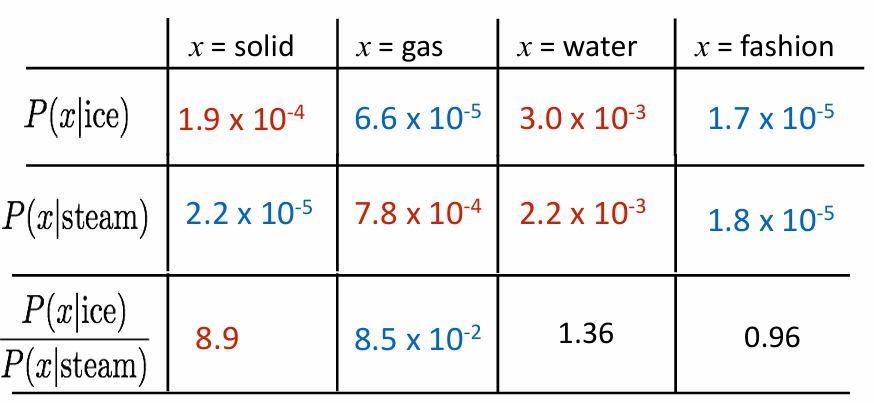
- Example
- 단어 ice와 steam은 둘 다 물과 관련 있음
- solid는 ice와 steam 중 ice와 훨씬 더 강하게 연결되어 있음
- ratio가 크거나 작을수록 의미 차이를 잘 드러내고, ratio가 1에 가까우면 의미적으로 차이가 없다는 뜻
- 따라서 단어의 의미를 vector difference로 표현 가능
Mathematical formulation
- 단어 벡터 $ w_i $
-


Loss function
손실 함수 정의
두 단어 사이의 내적이 동시 등장 횟수의 로그값에 근사하도록 학습시키기 위해서 GloVe는 아래의 손실 함수를 최소화함$$
J = \sum_{i,j=1}^{V} f(X_{ij}) (w_i^T \tilde{w_j} + b_i + \tilde{b_j} - \log X_{ij})^2
$$
구성 요소
- $ X_{ij} $: 단어 $ i $, $ j $의 동시 등장 횟수
- $ f(X_{ij}) $: weighting function
- 드문 단어쌍은 가중치를 낮춰 학습 안정성 확보
- 너무 자주 등장하는 단어쌍은 가중치의 최대치를 제한하여 학습에서 과도한 영향을 주지 않게 함
- $ w_i $, $ \tilde{w_j} $: 단어 벡터와 문서 벡터
- $ b_i $, $ \tilde{b_j} $: 바이어스 항
장점
- 효율적으로 빠르게 학습 가능
- 대규모 corpus에도 적용 가능
'Deep Learning > NLP' 카테고리의 다른 글
| [강의 정리] Seq2Seq Learning (0) | 2025.05.08 |
|---|---|
| [논문 리뷰] Efficient Estimation of Word Representations in Vector Space (0) | 2025.03.04 |
| [논문 리뷰] Attention is All You Need (0) | 2025.01.05 |
| [논문 리뷰] Labeled LDA: A supervised topic model for credit attribution inmulti-labeled corpora (0) | 2024.12.20 |
| [강의 정리] CS224n 1. Introduction and Word Vectors (1) | 2024.11.15 |



